One Agent, One Machine
 We built remote coding agents where a Slack message turns into a PR. Now, 40% of our PRs start there.#elixir #ai #agents #flame #claude-code #infrastructure
We built remote coding agents where a Slack message turns into a PR. Now, 40% of our PRs start there.#elixir #ai #agents #flame #claude-code #infrastructure
note: I’m just saying Elixir for simplicity, but some of you may know when I’m actually meaning erlang 😉
Remote Agents are the next step
OpenAI recently released their Elixir agent orchestration library symphony and it inspired me to share about our agent, Shelly. Both projects are examples of the power of Elixir to run parallel processes. In their model, Symphony spawns local Claude agents in separate workspaces. Why stop there? We looked at existing tools, but inevitably it meant teaching another system how to build our dev environment and provide them with all of our credentials. We wanted something that behaved more like an Elixir system, and we already had everything we needed. We built Shelly as our remote agent Elixir app. Each agent is a fully provisioned, ephemeral fly.io machines, on demand. Anyone on the team can @Shelly in Slack, and the following thread is a dialogue with that running agent just for you.
Core idea: Treat each agent like an Elixir process, but give it its own machine.
Each Task Gets Its Own Machine
We wanted something that scaled to zero, had low overhead, and assumed from day one that agents can’t be trusted. Each agent is a fly.io machine that runs for the duration of that agent’s conversation. When no one is asking questions, we have no agents. Whether it’s a quick question or an hour-long plan.md, every agent gets its own resources. We rely on our .devcontainer as the foundation of the agent’s environment. Each session has our latest env, preinstalled dependencies, and MCP servers. On top of that, we layer a Dockerfile to handle Linux user isolation and route internet access through a proxy. That allows us to heavily restrict access from these machines. We built it with the expectation that malicious code execution is inevitable, and the blast radius should be as small as possible.
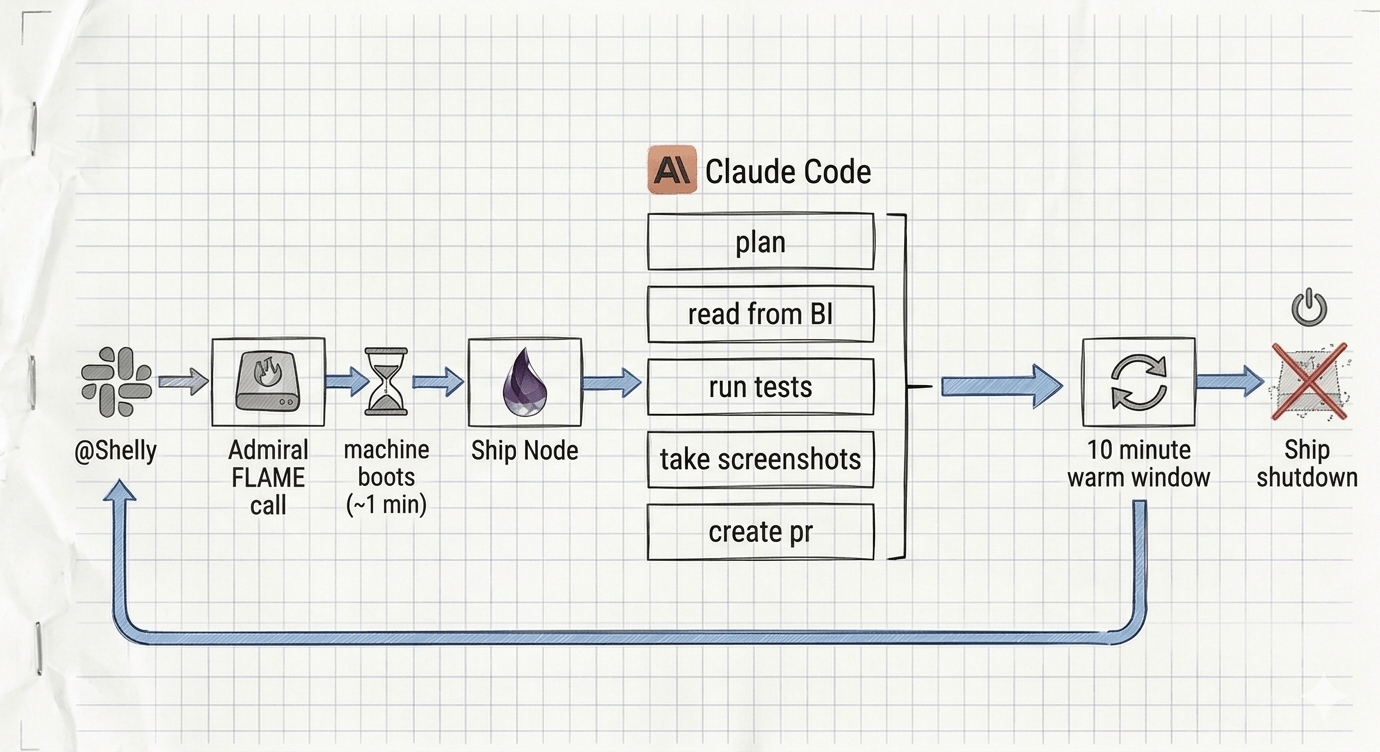
The full voyage: one Slack message boots a Fly.io machine, Shelly works autonomously, posts results back, then shuts down after a 10-minute warm window.
The Erlang Cluster Is the Superpower
The most exciting part to me is that each agent is actually running the Claude SDK through an Elixir process as part of the cluster. We call the main node the Admiral and each agent a Ship. That allows the claude tool calls to message the Admiral and ask permission. The Admiral may even make API calls with privileged access and return results to the Ship. As far as claude knows, it just uses the send_slack tool and behind the scenes the cluster allows the Admiral to send the slack to the correct thread. The Ship never has a slack token on the machine or in the conversation! We apply this to any risky tool or MCP, the agent doesn’t need direct access and that mitigates a lot of prompt injection fears.
tool :slack_reply, "Reply to the Slack thread that initiated this agent" do
def execute(%{message: message}, frame) do
GenServer.call(frame.assigns.admiral_pid, {:tool_call, :slack_reply, %{message: message}})
end
end
My teammate John and I made the MVP in a week. I finally got use Chris McCord’s FLAME for machine lifecycle (think, lambda, but our app boots on the runner), the claude_code Elixir library as the SDK, and Erlang distribution as the glue. Shelly monitors all of the remote machines as members of the cluster, and FLAME handles spawning them and destroying the Fly.io machines. One agent per machine is the Elixir process philosophy at fleet scale: isolated state, failures that stay contained, and coordination through message passing.
{
FLAME.Pool,
name: Shelly.Fleet,
min: 0,
max: 10,
max_concurrency: 1, # 1 agent per machine
idle_shutdown_after: :timer.minutes(10), # pseudo code
}
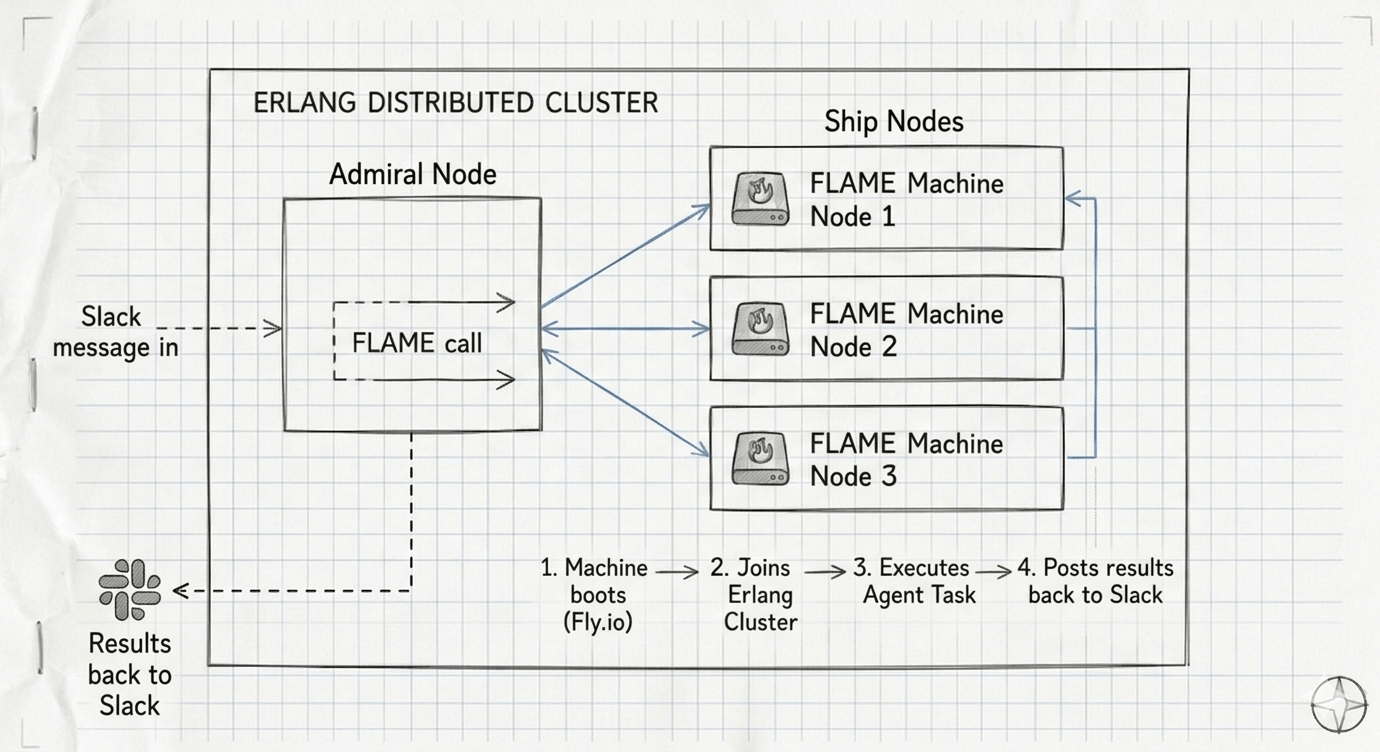
Each FLAME machine joins the Erlang cluster. The primary node (Drake) can observe every running ship and ships call back for privileged operations.
Where we are today
Shelly had a bigger impact than I expected. Our CTO uses it to kick off dev tasks between calls, avoiding worktrees and babysitting. Our PM uses it to explore “what would it look like to…” and “find me all of the outreach we do via SMS.” Our Disaster Experts are giving us more product feedback than ever because they can ask for it directly, eg. “I made a typo and I need an edit note button.”
This is a real project with real problems, ~2 minute cold starts are real for our big devcontainer (playwright is part of that problem), distributed debugging can be hard, there are network complexities running all of these machines. Even so, we’ve averaged 17 PRs per week (our 2 engineer, 1 CTO team averages ~40) originating from Shelly over 5 weeks, and 7 non-engineers have had PRs merged this month. I wish I could say I foresaw how valuable the devcontainer would be when I advocated for the investment, but it has paid off many times over now.
I’m toying around with the next phase, which isn’t just more MCPs, but specifically linking to things like Sentry to automatically triage, and log access to allow self-correction. Note, these agents push PRs that we review, we aren’t completely unhinged (yet…). We didn’t plan this architecture, but followed the natural Elixir model and it fit surprisingly well.