When and What to share between Microservices
Exploring the best way to handle the extraction of common code related to the persistence logic.
Service oriented architectures allow us to extract code further than traditional monoliths. This architectural freedom can make apps even more understandable than a monolith, but also removes the safety net of a predefined structure.
The Proposal
My team wants to add a new microservice that persists some data. It will have its own domain, but it should give us some of the same features that are found in one of our existing services.
Our Existing Service
- Persists data
- Tracks creation and modification of the model
- Uses a simple ORM with no out-of-the-box tracking
We wrote a feature called Date Tracking, and I will focus on it to describe the different possible extractions. The Date Tracking is implemented with two fields, created_date and last_modified_date. The implementation is straightforward: append the fields to our ORM model and include a migration to add those columns to our DB table. Logic-wise, the feature is simple–when the model is changed the last_modified_date is updated, and when the model is inserted for the first time the created_date is set. We want to implement this in our new service in the best way possible.
The Requirements
- It does not cost additional effort to share code this way
- It includes Date Tracking
- It models an arbitrary domain
- created_date, last_modified_date
We have already written the functionality once and we want to reuse that code in the best way possible. We are concerned with DRY principles, readability, flexibility, time to implement, and technical debt.
To simplify the discussion, we are going to make some assumptions.
- These two projects are not in the same code base
- There is an easy way to share code with an internal dependency
Let’s explore some solutions
- Repeat yourself.
- Extract to a superclass (Inheritance)
- Extract to a separate model (Composition)
Repeat Yourself
This is where everyone starts, the simplest case. This is the original implementation of the Date Tracking feature. It is used once, so the logic lives in our original domain model. That code can easily be copied into a model in another part of the code. Repetition takes no additional understanding, and it’s the fastest way to add the same functionality to another model. This gives complete decoupling between service, and a maximal amount of flexibility to each one. This is more viable than you may expect (No Shared Code - Chad Fowler)
The benefit to keeping this strategy is that everything you need to understand the service is written there for you, giving high readability. Unfortunately, there is going to be low parity across services, because you will improve the code as you copy it to others and each service will have slight variations. The scariest part of this is that the longer you resist choosing a different pattern, the higher the cost of fixing it becomes!
There seems to be general fear around disobeying DRY principles, but depending on the use case, it may be the right call. Duplication means you need to update each use individually, but that is possibly cheaper than refactoring a failing abstraction.
If you find yourself passing parameters and adding conditional paths through shared code, the abstraction is incorrect.
If we don’t expect to use the Date Tracking functionality again, then why spend the time to extract it cleanly? If being DRY means that you are writing more code to accommodate each specific use, then I think it’s safe to say that something is wrong.
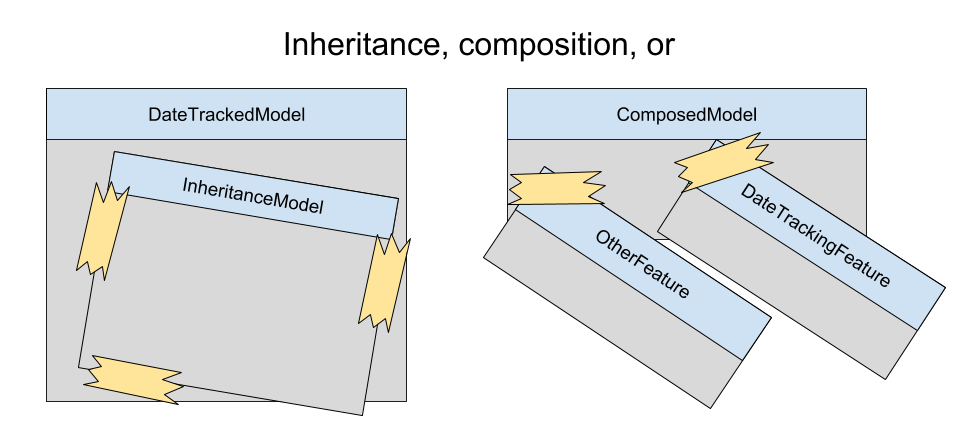
Extract (Inheritance)
This pattern is a centerpiece of OOP. If it’s common, then extract it into a superclass. For our Date Tracking feature, we can move the created_date and last_modified_date fields into a superclass, then extract that class into our shared library. Each service that extends our superclass only needs to define a fragment of the actual domain model. It’s good that your service only describes what is specific to its domain, but the service still needs to define the DB schema. In your code there will be fields that didn’t exist explicitly in your domain model, and your schema definition and migrations will have to account for that.
The benefit to this is parity across your services, because they are using the same code. You can update everything in one place, and you have smaller services in general. This is a double-edged sword because every time that class is extended, it inherits all of the features and many languages only allow single inheritance.
Specifically in the case of extracting persistence logic, we can find confusion when we need to modify code that relates to the fields that are only defined in the superclass. Having the definition of your domain model split between two code bases can cause headaches for new developers or someone trying to refamiliarize themselves with your app. On the other hand, this approach is fast, and simple. With a fairly stable code base where changing the functionality of a feature like tracking seems unlikely, extraction via inheritance will probably give you the best bang for your buck.
Extract (Composition)
It’s possible that Date Tracking of a model in the original table isn’t the best solution. We can actually have a shared table that has columns for the history and foreign keys to our original tables. This way, the extracted module can be responsible for only its own table, and leave the model that it tracks untouched. Like the inheritance extraction we will need a migration, but we won’t need to alter our original tables. The logic and model for our tracking table lives in the external module, but it allows for us to easily add or remove features without affecting our model. This is far more flexible than our inheritance design, but of course less flexible than just rewriting all of the code. Our domain models just declare that they are tracked and on change they update the tracking table.
The benefit here is the same degree of parity across the services, with the added benefit of readability. The models that are defined in your service are exactly as they are defined and they reference a relationship to a tracking table, which is entirely extracted into the external module. I might be honeymooning with this idea, but it seems like the best of both worlds. This solution has added complexity because of the additional table relationships, but I find that outweighed by the benefits.
Developers read far more code than they write, and you are writing your code to be read by other developers. Given that the code needs to work, the best way to keep that code working is making it maintainable by other developers, where reading is a requisite to maintainability.
And the thing of it is…
Each of these approaches comes with some benefit to ease of implementation, or ease of extension. Unfortunately, there isn’t a hard and fast solution for which path to choose. If you only expect to use this twice, then maybe the copy and paste solution will be fast and won’t cause problems down the road. Inheritance is the next easiest, and also won’t bite you unless you really start using the library a lot (>3 times). Personally, I am pretty strong on Composition over Inheritance and I think the last solution is the most elegant.
The transition from monolithic apps to more service oriented architectures has made this debate more one sided for me. More frequently I find myself reaching for a library that compliments my code, instead of rebasing my code on top of theirs. Speed of development is a real argument against the compositional approach, but I really appreciate readability, and the idea of plug-and-play features.
Accolades
A big thanks to RJ Dellecese and Sam Roberts for all of the editing. Honestly, without their constant proofreading this would have been gibberish.